Building a Small yet Highly Capable LLM-as-a-Judge: Fine-Tuning Gemma 3 4B for Evaluation Tasks
November 20, 2025 · Hakan Doğan
Originally published on Medium
Open-source language models have made incredible progress in reasoning and instruction following — yet they still struggle with one crucial skill: evaluation. How can we train small models to judge long-form text with the nuance and consistency of giant models such as GPT-4?
In this project, we built a compact, open-source LLM-as-a-Judge by fine-tuning the Gemma 3 4B model on two complementary datasets from Prometheus-Eval:
- Feedback Collection → absolute scoring (1–5)
- Preference Collection → pairwise ranking (A vs B)
We trained two specialized models, then merged them with Nuslerp using the MergeKit library — creating a single, balanced evaluator capable of both scoring and ranking. With extensive evaluation and testing of this model, we found out that it outperforms the previously open-source SOTA model fine-tuned on this dataset despite being much smaller. We also measured the consistency among its evaluations and verified that it does a very good job without a specialized heuristic method.
Why Build an LLM-as-a-Judge?
Human evaluation remains the gold standard for measuring helpfulness, factuality, and coherence in model outputs. However, it is expensive, slow, and difficult to scale. We need automated evaluations to be able to increase the number of iteration cycles and make rapid progress.
LLM-judges fill this gap by learning to approximate human preferences through structured feedback data. A good judge model can:
- Score model outputs on dimensions like helpfulness, factuality, etc.
- Compare two responses and decide which one is better.
- Provide textual rationale for its judgment.
- Serve as an automated evaluation system for ongoing model training experiments.
Datasets: Prometheus-Eval Feedback & Preference Collections
Both datasets were released in Prometheus (2024) to teach open models fine-grained evaluation capabilities.
Feedback Collection — Absolute Scoring
- 1K rubrics, 20K instructions + reference answers, 100K responses + feedback
- Output format — Feedback:
<critique text> [RESULT] <1-5> - Trains models to assess responses against reference answers and rubric descriptions.
Preference Collection — Pairwise Judgment
- 1K rubrics, 20K instructions, 200K response pairs (A/B)
- Output format — Feedback:
<comparison text> [RESULT] <A or B> - Trains models to compare two responses and pick the superior one.
Dual Fine-Tuning Strategy
We fine-tuned two separate judge models:
- Feedback model on Feedback Collection
- Preference model on Preference Collection
We fine-tuned attention and MLP modules of the first model using LoRA with r = 64, LoRA alpha = 32, and LoRA dropout = 0.15 on top of the feedback collection. In parallel, we fine-tuned another model on top of the preference collection with R = 128.
Each model captured distinct judgment behavior: one mastered calibrated scoring, the other comparative reasoning.
Merging with Nuslerp (MergeKit)
To combine their complementary abilities, we used Nuslerp, a non-linear, spherical interpolation algorithm that merges weight spaces layer-wise for smoother semantic blending.
mergekit --base unsloth/gemma3-4b-it \
--models feedback_model preference_model \
--weights 0.5 0.5 \
--method nuslerp \
--output gemma3-4b-judge-mergedEvaluation Results
We evaluated all models on Prometheus-Eval/Feedback-Bench and Prometheus-Eval/Preference-Bench.
Feedback Model Results
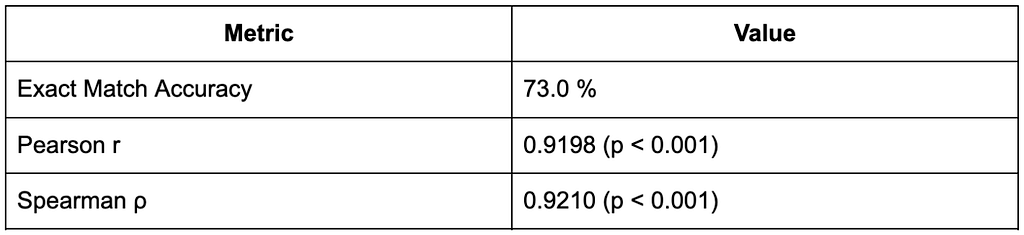
Preference Model Results

Merged Model (Feedback + Preference)

Base Model (google/gemma3-4b-it)

Comparison Summary

Our merged Gemma 3 4B-based judge matches or surpasses Prometheus 2 (8×7B) correlations while being significantly smaller.
Consistency Evaluation
TrustJudge is a probabilistic evaluation framework designed to make LLM-as-a-judge systems more reliable. Traditional evaluation setups often suffer from two key issues:
- Score-Comparison Inconsistency — where lower-rated responses can outperform higher-scored ones in pairwise comparisons.
- Pairwise Transitivity Inconsistency — where circular or contradictory preferences emerge (e.g., A > B > C > A).
To address these, TrustJudge introduces distribution-sensitive scoring, which converts discrete rating probabilities into continuous expectations for finer-grained judgments, and likelihood-aware aggregation, which corrects transitivity violations using bidirectional preference probabilities.
We experimented with the TrustJudge approach in our case. Although the method theoretically enhances evaluation consistency, in our experiments it didn't lead to any noticeable difference. This suggests that TrustJudge, despite being beneficial for zero-shot settings, may not provide additional benefits for task-specific fine-tuned models, since such models have already internalized the key evaluation signals during training.
Inconsistency in TrustJudge
We used the prometheus-eval/Preference-Bench dataset to analyze evaluation inconsistencies. For each sample in the dataset, we evaluated two responses and selected the one with the higher score. Then, we checked whether this response had been previously preferred over the other one. If not, we marked it as an inconsistent sample.
After running this process across the entire dataset:
| Metric | Result |
|---|---|
| Consistency | 77.83% |
| Inconsistency | 3.50% |
| Ties | 18.67% |
Limitations & Next Steps
Even though the model also does a decent job in non-English settings thanks to Gemma 3's multilingual capabilities, we did not run systematic benchmarks in these languages since the underlying dataset is exclusively in English. A natural next step will be to fine-tune the model explicitly for multilingual use cases.
The current models need reference answers to evaluate model responses. This is particularly useful to evaluate models against a validation subset where we already have a golden answer. However, another common use case is to evaluate responses supposed to be grounded on a given reference context. We will add support for such use cases as an upcoming improvement.